

いつも当店のブログをご覧いただきありがとうございます。この記事はオーティコン補聴器のカタログや当店ホームページに使用している専門用語を要約してまとめたものです。新しい用語がでるたびにアップデートしていく予定です。
VAC-J

VAC-Jは、オーティコン補聴器と九州大学の共同研究により、日本語の音響的特徴を考慮した補聴器フィッティング理論です。世界の補聴器フィッティング理論は欧米言語を基に設計されていましたが、日本語は異なる音響的特徴を持っているため、従来の理論では最適な補聴補正が難しいことが課題でした。
VAC-Jの概要
- 研究開始:2014年、九州大学とオーティコン補聴器(日本法人・デンマーク本社)の共同研究としてスタート。
- 研究内容:日本語の音響特性(発話努力によるLTASS:長時間平均音声スペクトル)を分析し、日本語話者に最適化した補聴器フィッティングの補正値を算出。
研究成果
- 日本語のLTASSは欧米言語のLTASSよりも低周波数レベルが大きく、高周波数レベルが小さいことを確認。
- 日本語を母語とする難聴者向けに、補聴器の利得を調整した新たなフィッティング理論を構築。
- VAC-Jは、欧米言語ベースの補聴器フィッティング(VAC)と同じ音声了解度を示しながら、日本語により自然でソフトな聞こえを提供することが確認された。
実用化と今後の展望
VAC-Jは、オーティコンの補聴器フィッティングソフト「Genie2」に搭載されており、ベロックスシリーズ以降の補聴器で利用可能です。日本語話者向けの最適な補聴器フィッティングが可能になり、より快適な聞こえの提供と補聴器満足度向上に貢献することが期待されています。
VAC-Jを実装した補聴器
- インテント1~4
- リアル1~3
- プレイPX1・PX2
オーティコンのフラグシップモデルはVAC-Jを搭載しており、同じモデル名(インテントなど)を称するモデルはVAC-Jを搭載しています。フラグシップモデル以外の名称の補聴器「ジルコン」や「ジェット」などはVAC-J非搭載です。
参考にしたサイト
モアサウンド・インテリジェンス
オーティコン補聴器「モア」に搭載されたインテリジェンス機能の中核をなす技術で、周囲の音を1秒間に500回スキャンして「音の情景」をリアルタイムで解析。ひとつひとつの音を明確なコントラストで際立たせ、脳へのアクセスを滑らかにサポートします。

主な仕組み
- ディープニューラルネットワーク(DNN)の活用 補聴器内部にDNNを搭載し、オーティコンが収集した1,200万件もの実世界の音データから学習済み。あらゆる種類の音の詳細と、理想的に聞こえる条件をDNNが理解しています。
- オーティコンは、補聴器の開発過程で360°球体マイクを使用し、実環境の音データを収集しました。この球体マイクは補聴器本体には搭載されていませんが、DNNの学習時に活用されました。収集した音を用いてDNNが学習し、補聴器が実際の環境に適応できるようになっています。
モアサウンド・アンプリファイアとの連携
- モアサウンド・インテリジェンスが音のコントラスト付けを担う一方、モアサウンド・アンプリファイアが高速・高解像度で必要な音だけを的確に増幅。両者のシームレス連携により、自然なバランスを保ったまま会話明瞭度を最大化します。
もたらされる効果
- 会話の聴き取りやすさ向上:背景ノイズを抑えつつ声の細部を強調
- 自然で疲れにくい聞こえ:脳が処理しやすい「音の全体像」を提供し、長時間装用でも負担を軽減
- 環境適応の滑らかさ:静かな室内から屋外の騒音下まで、刻一刻と変わる音場にシームレスに対応
モアにはほかに「クリアダイナミクス」「音空間認知機能」「サウンドエンハンサー」など複数のAIインテリジェンス機能が搭載され、“ブレインヒアリング”概念で脳の聞く働きを総合的に支援しています。
参考にしたサイト
モアサウンド・インテリジェンス3.0
オーティコン・モアに搭載されたAI技術「モアサウンド・インテリジェンス」は、3世代目AI補聴器「インテント」になりさらなる進化をとげました。それがモアサウンド・インテリジェンス3.0です。下記の解説では4Dセンサー(自分センサー)についての説明もありますが、自分センサー搭載モデルはインテント1と2です。3・4は自分センサーは搭載しておりませんのでご注意ください。

モアサウンド・インテリジェンス 初代 と 3.0 の主な違い
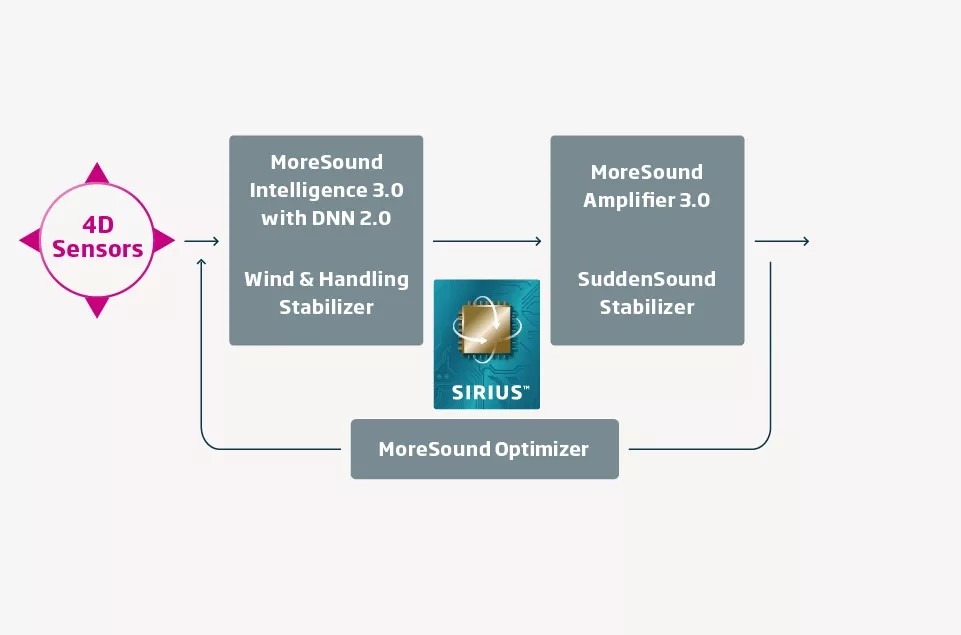
- じぶんセンサー(4Dセンサー)の搭載 ・初代:補聴器本体は周囲音のみをマイクで拾い、音響環境を解析。 ・3.0:世界初*の“4Dセンサー”(じぶんセンサー)を導入。360°の音響環境に加え、①自分の発話・周囲の会話、②頭部の動き、③体の動きをセンシングし、ユーザーの「聞きたい意図」をリアルタイムに反映する。
- DNN(ディープニューラルネットワーク)の進化 ・初代:DNN1.0を搭載。256チャンネルの学習で雑音抑制や会話強調を実現。 ・3.0:DNN2.0を新採用。学習チャネル数を24倍(256→約6,000チャネル相当)に増強し、より複雑・多彩な環境でも雑音抑制が約2dB向上、原音の自然さを保ったままの会話明瞭度アップを実現。
- モアサウンド・アンプリファイアの強化 ・初代:音のコントラスト付けと増幅を一つのステージで担う。 ・3.0:増幅ステージ「モアサウンド・アンプリファイア3.0」を新搭載。80Hz~10kHzまでの広帯域で、必要な音だけを的確にクリアに増幅することで、より自然な音質と高い会話理解度を両立。
- 新プラットフォーム「Sirius(シリウス)」チップの採用 ・初代:従来チップで音声処理を実現。 ・3.0:新開発の補聴器専用チップ「シリウス」を搭載し、先進的な信号処理アルゴリズムや4Dセンシング、DNN2.0を高速・省電力で駆動。装用快適性も向上。
- ブレインヒアリング技術の深化 ・初代:“脳へのアクセス”を意識したサウンドコントロール。 ・3.0:じぶんセンサー+高度AI+シリウスチップの連携で「聞きたい情報」を脳に届ける、いわば“ブレインヒアリング”を次なる高みへ引き上げる構成に進化。
モアサウンドインテリジェンスの違い(モア VS インテント1・2)
| 項目 | モア・プレイPX (モアサウンドインテリジェンス) | インテント1・2 (モアサウンドインテリジェンス3.0) |
|---|---|---|
| センシング技術 | 周囲音のみをマイクで拾い、音環境を解析 | 4Dセンサー(じぶんセンサー)を導入し、360°の音環境+ユーザーの発話・頭部・体の動きを分析 |
| DNN(ディープニューラルネットワーク) | DNN 1.0(256チャンネル学習) | DNN 2.0(約6,000チャネルで学習し、雑音抑制+自然な音質向上) |
| 音の処理速度 | 1秒間に500回のスキャン | 1秒間に最大700回のスキャンでよりリアルタイムな適応を実現 |
| ノイズ抑制 | 雑音抑制 最大10dB | 最大12dBの雑音抑制と、言語手がかりの保持率35%向上 |
| モアサウンド・アンプリファイア | 音のコントラスト付けと増幅を一つのステージで担う | モアサウンド・アンプリファイア 3.0が広帯域(80Hz~10kHz)の増幅を実現 |
| プラットフォーム(チップ) | ポラリス | 新開発「Sirius」チップで高度AI処理+省電力化 |
| ブレインヒアリング技術 | 脳へのアクセスを意識したサウンドコントロール | じぶんセンサー + DNN 2.0 + Siriusチップの連携で、ユーザーの聞きたい意図に適応 |
| 適応環境 | 基本的な騒音抑制+会話強調 | より多様な環境に適応し、雑音下でも自然な聞こえを維持 |
| 対応機種 | オーティコン モア | オーティコン インテント(インテント1・2のみ「じぶんセンサー」搭載) |
じぶんセンサー(4Dセンサー)
じぶんセンサー(4Dセンサー)は、オーティコンの補聴器「インテント」に搭載された革新的な技術です。従来の補聴器は音響環境を検知することはできても、ユーザーの意図を理解することは難しかったですが、じぶんセンサーは ユーザーの「聞きたい」ことを感知し、必要な音を届ける ことを目的としています。
じぶんセンサーの仕組み
- 音響環境:周囲360度の音の情景を収集し、環境の変化に適応。
- 頭部の動き:ユーザーの頭の動きを検知し、コミュニケーションの状況を理解。
- 身体の動き:空間認識をサポートし、必要に応じて聞こえの調整を行う。
- 会話活動:会話が行われているかをモニターし、会話音声を優先的に処理。
じぶんセンサーのメリット
この技術により、ユーザーは より自然な聞こえ を体験でき、騒がしい環境でも 会話の明瞭度が向上 します。また、補聴器が ユーザーの意図に即応 することで、より快適なコミュニケーションが可能になります。
目次
サウンドエンハンサー
サウンドエンハンサーは、オーティコンの補聴器に搭載されている機能で、特に騒がしい環境での会話の聞き取りを向上させることを目的としています。これは、補聴器が周囲の音の状況を分析し、ユーザーが聞きたい音を強調することで、より快適な聞こえを提供する技術です。
サウンドエンハンサーの特徴
- 騒音環境での聞き取り向上 周囲の雑音を抑えながら、会話音を強調することで、騒がしい場所でもスムーズなコミュニケーションが可能になります。
- 適応型音処理 環境の変化に応じてリアルタイムで音の調整を行い、ユーザーの聞こえを最適化します。
- ユーザーの聞こえの好みに合わせた調整 3段階の設定が可能で、ユーザーの好みに応じて聞こえの強調度を調整できます(インテント1の場合)
どのような場面で役立つか?
- レストランやカフェなどの騒がしい場所での会話
- 会議や講演など、複数の話者がいる環境
- 公共交通機関でのアナウンスの聞き取り
インテント1の場合
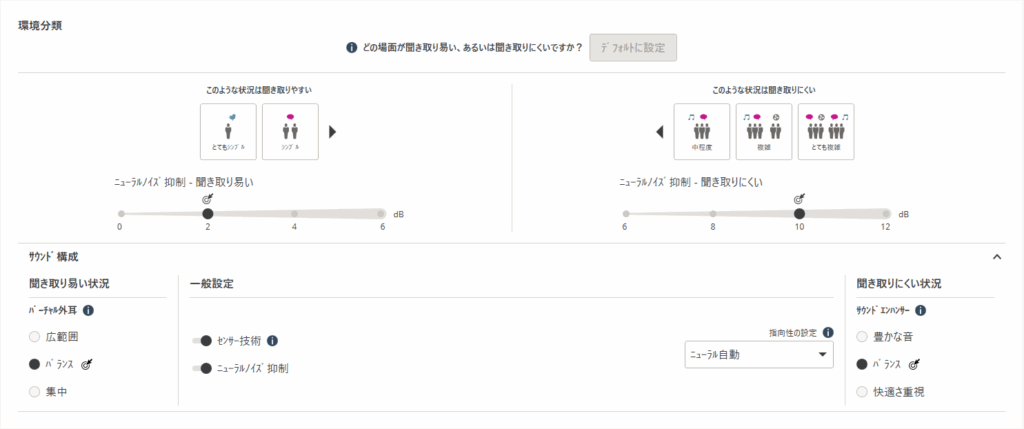
聞き取りにくい状況を見ていただくと「豊かな音」「バランス」「快適さ重視」の3種類から選ぶことができます。
インテント3の場合
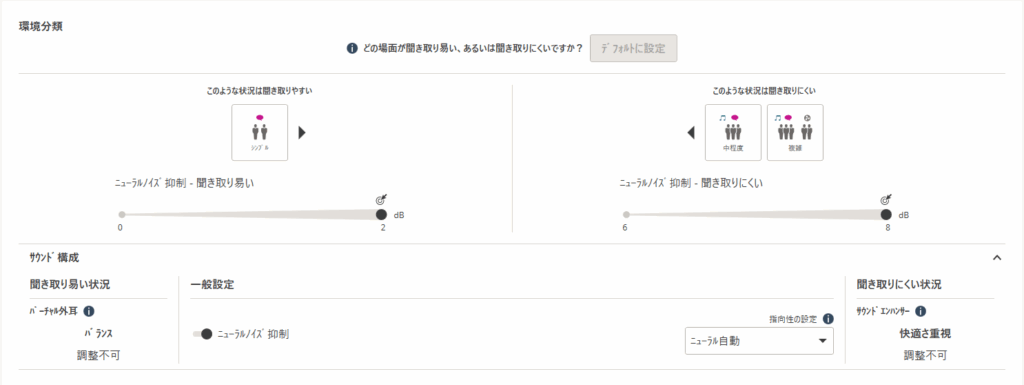
聞き取りにくい状況のラジオボタンがなくなり、快適重視のみの設定になります。
バーチャル外耳
バーチャル外耳(Virtual Outer Ear)は、補聴器のマイクが耳の後ろにあることで失われる 「耳介による空間的な音の手がかり」 を補完する技術です。これは、オーティコンの 「より良い音の知能」(MoreSound Intelligence) に組み込まれた重要な機能の一部です。
バーチャル外耳の設定
バーチャル外耳には、ユーザーの空間認識のニーズに応じて選べる 3種類のピンナ(耳介)モデル があります。
- バランス 前方と後方の音のバランスを均等に保つ標準設定。様々な環境で自然な聞こえを提供。
- 広範囲 側面や後方の音を強調し、より広い音場を認識できるようにする。屋外や騒がしい環境での聞こえ向上に役立つ。
- 集中 前方の音に集中し、会話の明瞭度を向上。静かな環境で話し相手の声をより聞き取りやすくする。
バーチャル外耳の役割
- バーチャル外耳は 空間的な明瞭化処理(Spatial Clarity Processing) と連携し、補聴器のマイク位置による影響を補正。
- 空間バランサー(Spatial Balancer) と組み合わせ、騒音下でも音源のバランスを最適化。
- 神経明瞭化処理(Neural Clarity Processing) によって、深層学習モデルを活用し、より自然な聞こえを実現。
この技術により、補聴器装用者は より正確な音の空間認識 を得ることができ、快適なコミュニケーションが可能になります。

